Spawn for development teams
Introduction#
Spawn offers many advantages for teams that might be used to using shared development environments or local database servers running on developers' machines. This article gives a case study of how a team at Redgate made the transition from using local database servers and shared environments to using spawn to create ephemeral, reproducible database servers on demand.
Current setup#
The application is a simple web app - there is a backend API server that needs to talk to a SQL Server instance and web frontend:
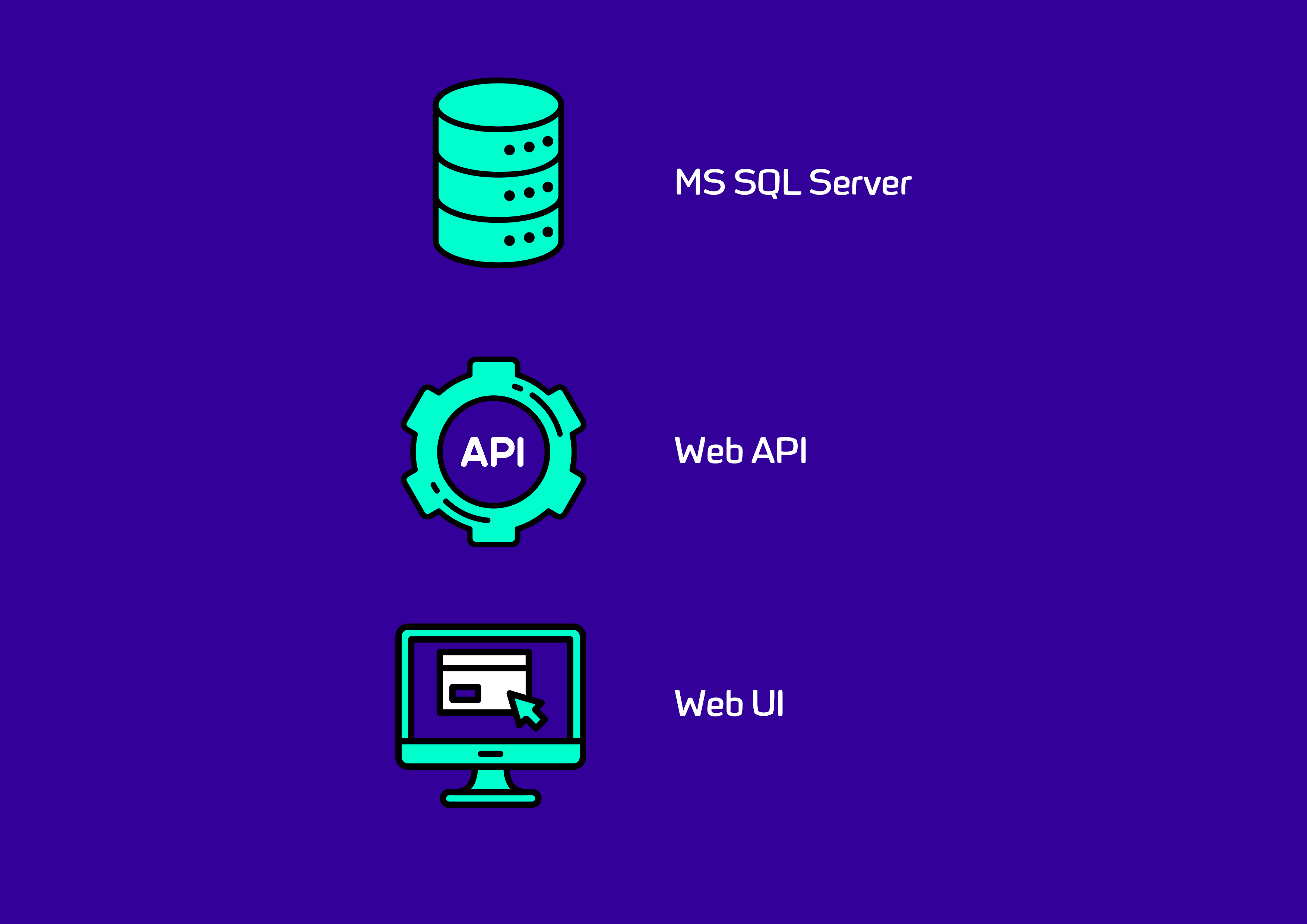
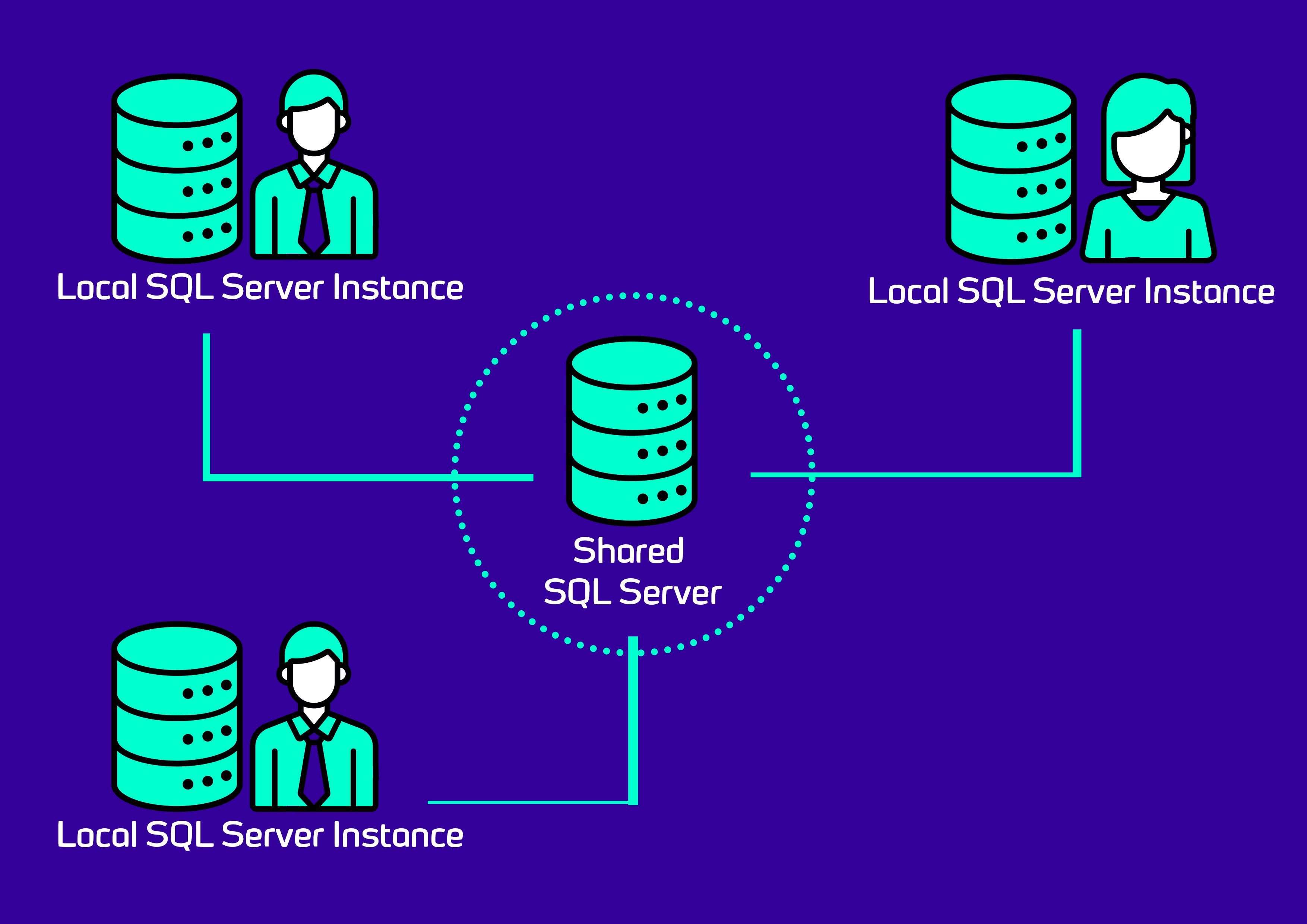
Each developer runs a local instance of SQL Server on their development machine. These instances contain databases that are typically quite small and contain only 'toy' data; they are not representative of the databases that will be used in production. In addition to these dedicated local instances, there are also some SQL Server instances that are available to the team as a whole, and are shared by all developers on the team. These shared instances typically contain larger databases that are more realistic and representative of the kinds of databases that will be found in production. The situation is summarized in this image:
Problems solved by spawn#
spawn is a good fit to improve the developer experience in such a setup for these reasons:
Reproducibility of development environments: with each team member running their own SQL Server instance there is no easy way to share database environments between team members. Consequently, a bug that is reproducible on one developer's machine may not be reproducible on one someone else's.
spawnallows all team members to use the same data image, thus ensuring consistency in the database layer across all developers' machines.Cheaper integration tests: The test pyramid is predicated on the assumption that unit tests are the fastest and most reliable tests to run. While this still holds true with
spawnand other container technologies, they make integration tests easier, less flaky and no longer require maintenance of external infrastructure. This makes integration testing more viable, increasing confidence in the system as a whole.
Creating and sharing a development image#
The first step to adopting spawn within a development team is to create a data image. While it is possible to use a backup as the source for the image, it is preferable to use scripts to create it so that those scripts can be placed under source control.
With the scripts folder in place, the next step is to use it to create the image. This is done by creating a simple .yaml file describing the image to be created:
We can indicate which GitHub teams should have access to the image by specifying the teams field. An image can be shared with multiple GitHub teams; here the image is shared with just one team, red-gate:dev-team-one.
The source scripts folder and this .yaml file should be versioned alongside the application code.
With this .yaml file created, use spawn to generate the data image:
Creating your data container#
Once the image is created, each member of the team can create new data containers from it. To create a new data container from the image:
Once the command completes you should see a connection string. This is the connection string for your own private data container based on the shared data image.
Using your data container#
One of the key advantages of working with spawn hosted instances over instances that you manage yourself is the ability to snapshot and roll back the state of your databases. This ensures that your instance is always in a consistent, known state for your development workflow. To create a snapshot of your data container:
Once this snapshot is created, you can continue to work with your data container as normal but with the added safety net that you can restore your instance to the last known state at any time. To restore your data container to the last saved revision:
Advantages of working in this way#
Having followed these steps, the database setup for each developer on the team looks like this:
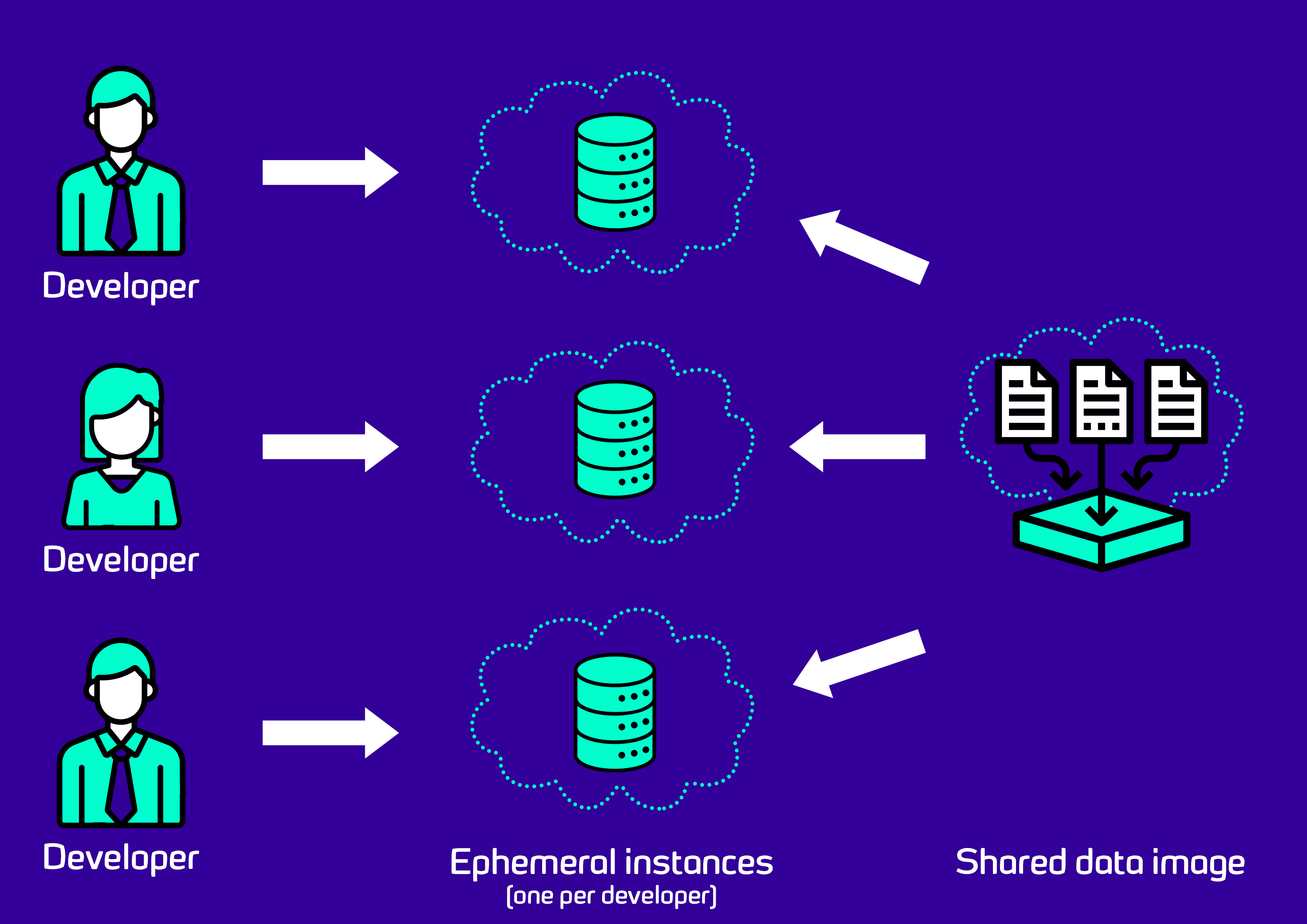
Each developer is now using their own cloud-hosted development database server. These instances can be snapshotted and rolled back independently of each other. Each instance shares the same base data image, ensuring consistency of schema and data between the instances.
By using spawn to host reproducible, ephemeral database instances the developer experience has improved significantly:
- There is no longer a need to run a SQL Server instance locally in order to do application development. This makes setup and onboarding of new team members less onerous.
- Development SQL Server instances are no longer shared between team members; such shared instances can suffer from having multiple team members treading on each other's toes, and could quickly get into inconsistent states when accessed by different versions of the application.
- There is no infrastructure to manage; all database instances are hosted and ephemeral - they can be taken down and recreated in seconds.
- All developers can use the same data image for their development databases, but have separate data containers. Having everyone on the team using the same image helps with reproducibility of issues caused by the data in the database - bugs should be easily reproducible by all team members because they all have the same test data.
- The shared data image only needs to be created once, so it can be a large, realistic example of a customer environment. Recreating such an environment from scratch multiple times, once per developer, can be very time consuming.
- Taking snapshots of data containers and periodically resetting back to them allows development databases to always be in a clean, consistent known state.
Icons made by Freepik, Becris & Prettycons from www.flaticon.com